All articles
Industrial Leaders Turn Unified Data Pipelines Into A Scalable AI Advantage Across Plants
Jan Hoscan, VP and Head of Industrial at Everpure, argues that industrial AI succeeds or fails on whether companies can turn fragmented IT and OT data estates into unified, governed, AI-ready infrastructure.

We need a single data plane, a single control plane, and a single data pipeline that can feed those machine learning models.

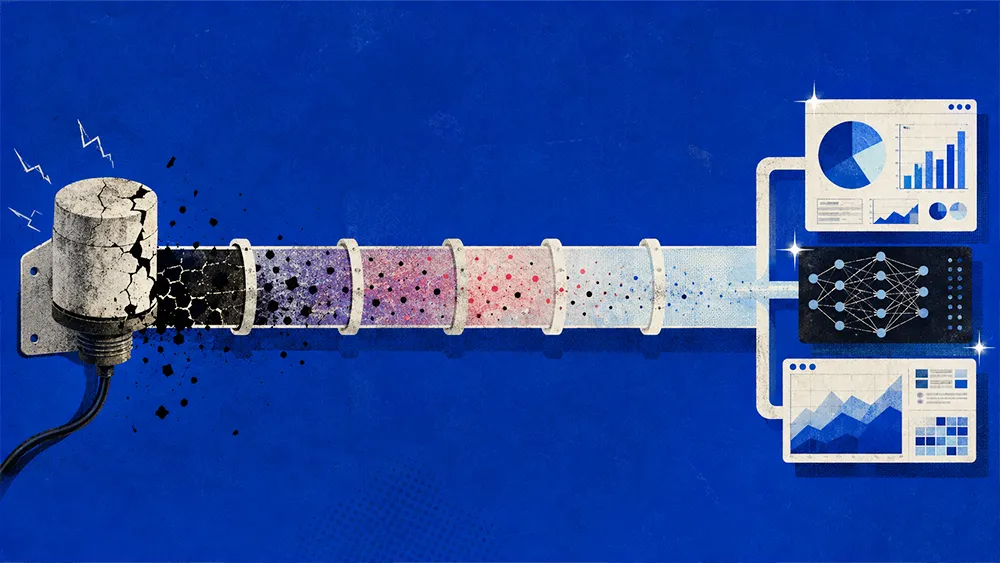
Industrial companies are pouring money into AI models and GPU clusters, then watching much of that capacity sit idle. The reason is rarely the algorithm. It's that manufacturing, R&D, operations, and enterprise IT have grown up as separate data estates that don't talk to each other, and AI cannot run at scale on top of that fragmentation. The work of unifying those estates is what now separates the industrial firms pulling ahead from the ones falling behind.
Jan Hoscan is Vice President and Head of Industrial at Everpure, where he leads strategy across automotive, manufacturing, energy, and process industries. His career spans general management, engineering, and dealmaking roles at Intel, Intel Capital, Red Hat, and Everactive, giving him a view of the industrial stack from both the technology and the investment side. He sees the convergence of information technology and operational technology as the defining shift of the moment.
For most of industrial history, every use case carried its own bespoke or segregated stack. Hoscan argues that AI is forcing those walls down because machine learning only works when the data underneath it is unified. "There is a great convergence to take advantage of the AI and machine learning and analytics emergence, because that requires unifying the data lakes, creating a single data plane, a single control plane, a single data pipeline," he says.
He maps the territory across five domains, from product engineering and validation through autonomous-driving data pipelines, smart-plant architecture, enterprise IT, and the cross-domain analytics layered on top. Each plant, in his framing, is a mini enterprise, and the push toward unified architecture is what lets all of them feed the same models.
Data as the bottleneck
The industry's attention is misallocated, in Hoscan's view. Teams obsess over algorithms while the constraint sits upstream in how data is stored, moved, and prepared.
"The real bottleneck is data. It's not the algorithms," he says. The consequences are expensive. Fragmented storage and weak throughput starve the most costly assets a company owns. "If you can't process and present your data fast enough to the GPU clusters, you're not training your models effectively," he says, describing farms worth hundreds of millions of dollars left half idle while they wait to be fed. Engineers stall the same way, sitting on their hands while a simulation finishes before they can resume work.
Fragmentation also widens the attack surface. Hoscan points to the ransomware attack that halted a major UK automaker for weeks, an incident later estimated to have cost the broader economy billions, as what happens when OT and IT stacks are too splintered to patch effectively. Cost compounds it from a third direction. As data volumes explode, storage, egress, and GPU fees can become the second-largest line item after salaries, a pressure that mirrors the broader race to scale compute.
Governance, non-negotiable
Before any of this scales, Hoscan insists governance be treated as foundational rather than an afterthought. Without a verifiable chain of custody, the data feeding a model cannot be trusted.
"If you don't have a strong chain of custody in your data, your data quality cannot be guaranteed. As a matter of fact, it may even be corrupted," he says. Feeding raw or uncontrolled data into a model risks poisoning it, while careless labeling can bake in bias that changes how the system behaves.
The discipline spans provenance, authorization, labeling, curation, storage, and protection, and it has to be enforced from day one, an approach consistent with how others frame automated data governance for AI. "You can evolve it, but it needs to be based on enforced rules."
One lighthouse, then scale
The execution failure Hoscan sees most often is ambition without structure. Large enterprises run hundreds of disconnected pilots and call themselves AI-forward, when they're really experimentation-forward without selection criteria.
"You need to have one ambitious but well-scoped lighthouse initially. Don't try to boil the ocean," he says. The pattern he advocates is a single cross-functional use case built with expansion in mind, then standardized into repeatable AI pods, units that bundle hardware, software, pipelines, and models, with governance and cyber resilience built in.
The harder discipline is pace. Pin a decision today, and the technology may shift in six months, so an organization's architecture has to absorb improvements continuously, which Hoscan calls moving at the line rate. Lag too far, and the frontier pulls away. Chase it constantly, and nothing gets proven, a tension visible across the intelligent industrial operations shift now underway.
That balance is the real test of industrial AI maturity. The companies that endure, Hoscan argues, will be the ones with the discipline and the balance sheet to keep unifying their data while staying close to the frontier. The rest face a harder fate. "Those who don't either are going to fall behind and become uncompetitive, or they're simply not going to exist in a few years."